OpenAI-Proof Q&A
OpenAI's models try to crack major bugs that previously took OpenAI researchers >1 day to solve.

With today’s release of GPT-5.1-Codex-Max, OpenAI updated the results of one of the most interesting extant AI model benchmarks, the unfortunately named OpenAI-Proof Q&A.
What is this benchmark?
Take 20 research and engineering bottlenecks that OpenAI actually encountered in the past, each of which required over a day for the OpenAI team to solve. These bottlenecks include “unexpected performance regressions, anomalous training metrics [and] subtle implementation bugs”, which actually represented delays to major projects and “in some case influenc[ed] the outcome of large training runs and launches”.
Give the model access to a container with code access and run artifacts, permitting it to use historical code, logs, and experiment data.
Ask the model to diagnose and explain the root cause of the issue.
Each of the model’s solutions is graded pass@1 (one try only!).
This benchmark is very relevant to accelerating - and eventually automating - AI research. Imagine the time and resources that could be saved quashing a major bug if GPT-x could diagnose and identify it even 50% of the time (instead of the OpenAI team spending 1+ days identifying and fixing it).
I particularly like that, instead of using toy problems (which are often of questionable relevance to real-world AI use cases, but plague nearly all popular LLM benchmarks), OpenAI-Proof Q&A measures the model’s performance on major bugs that OpenAI has actually encountered in the past. And the model’s performance is judged on a pass@1 standard - none of that “well, it got the solution right once out of the twenty times we ran it, so we’ll call that a pass” nonsense.
Here’s how OpenAI’s models have done on this benchmark to date:
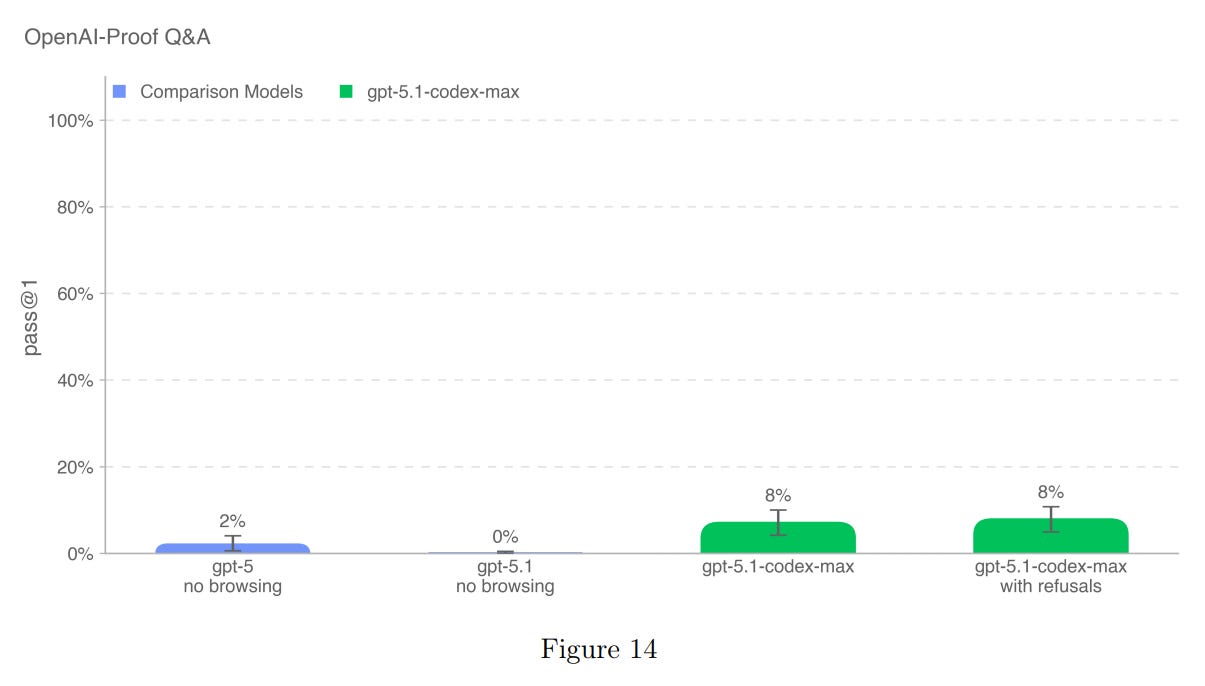
GPT-5.1-Codex-Max scored 8%1 (with and without refusals), beating the previous SOTA (GPT-5, which scored 2%).
Note: It is not clear to me how much of the delta between GPT-5 and GPT-5.1-Codex-Max was due to the fact that GPT-5 had “no browsing”. Did GPT-5.1-Codex-Max have access to browsing (I assume yes)? If so, how much did this skew the score?
Regardless of comparability to GPT-5’s score, the result achieved by GPT-5.1-Codex-Max is quite impressive. Look for further updates to OpenAI-Proof Q&A as more powerful OpenAI models are released over the next 12 months.
It is not clear how a benchmark consisting of 20 problems can yield scores that are not divisible by 5. My best guess is that each of the 20 problems was given to different instances of GPT-5.1-Codex-Max multiple times, resulting in a more granular aggregated score - but this has not been confirmed by OpenAI.